Как сохранить данные веб-сервиса
Существует множество причин, почему вам нужно скопировать данные из какого-либо сайта или сервиса в сети интернет. Вы хотите использовать их в дальнейшем в оффлайне, возможно, интересующие вас данные могут быть удалены или у вас в дальнейшем может не быть к ним доступа, кто-то привык копировать на диск интересующую его информацию.
Если информацию можно загрузить и увидеть в браузере, то ее, как правило, можно скопировать себе на диск. Существуют также платные и бесплатные программы, которые позволяют скопировать сайт целиком себе на компьютер.
Но когда речь заходит о сохранении информации из какого-либо веб-сервиса, то стандартными средствами уже не обойтись. Необходимо использовать специальные программы - парсеры для извлечения и сохранения информации из веб-сервиса.
Парсер (от английского слова parse - разобрать) — это программа или её часть для сбора, систематизации и преобразования информации в структурированный формат. Она позволяет обрабатывать большие массивы данных в автоматическом режиме.
Парсеры обычно используются в интернет-маркетинге для сбора и анализа информации у конкурентов, или проверки собственных сайтов.
Парсеры можно также использовать и для сбора, структурирования и сохранения информации с внутренних веб-сервисов компаний, когда это необходимо и согласовано.
История одного архива
Российское подразделение иностранной компании несколько лет реализовывало проект по цифровизации архива сервисного центра.
За несколько десятков лет работы накопилось огромное количество бумажных документов, связанных с вводом в эксплуатацию поставленного оборудования, проведением инспекций, модернизаций и ремонтов. Периодически, при обращении заказчиков, эти документы нужно было искать в бумажном архиве для анализа текущего положения на объекте и предоставления консультаций. Но работать с бумажными документами не удобно, затратно, а иногда и вообще не возможно, если сервисный центр это распределенная структура, расположенная в нескольких городах.
Российское подразделение самостоятельно организовало и профинансировало проект по цифровизации архива: в течение нескольких лет архивные документы бережно сканировались, классифицировались и загружались в корпоративную базу данных об установленном оборудовании.
В 2022 году иностранная компания решила уйти с российского рынка и закрыть доступ ко всем своим внутренним сервисам для новой компании, которая "выкупила" бизнес в России. Механизма копирования или переноса данных об установленном оборудовании уходящая компания не предоставила, а это информация о примерно 45000 единицах установленного оборудования по всей России и порядка 400 Гб уже отсканированных и структурированных документов, необходимых для эффективной работы как самого сервиса, так и отдела продаж.
Спасение данных
Для обеспечения возможности дальнейшего использования данных об установленном оборудовании в новой российской компании есть несколько вариантов:
- Договориться с глобальным менеджментом, а затем и с администраторами базы веб-приложения о процедуре копирования данных. Это самый правильный и цивилизованный вариант. Но здесь, как правило, всё сложно в условиях ограниченности во времени и ресурсах , а самое главное, низкой важности этой задачи для иностранного менеджмента.
- Ручное копирование информации. Это целесообразно, если количество информации или файлов незначительно. Иначе это может занять очень много времени, отвлечь много людских ресурсов, повлечь множество ошибок и неточностей. Все это очень затратно.
- Организовать автоматическое копирование данных с помощью разработанной под заказ программы-парсера.
Рассмотрим подробнее как можно организовать копирование данных с помощью парсера на примере веб-сервиса базы установленного оборудования производственной компании и на что нужно обратить внимание.
Получите формальное согласие на копирование своих данных
Как правило, с этим никаких проблем быть не должно, ведь от владельцев веб-сервиса не потребуется никаких других действий, кроме как согласовать автоматическое копирование например посредством ответного письма в электронной почте.
Желательно согласовать максимальную нагрузку на сервер веб-приложения:
- какой учетной записью (записями) можно воспользоваться для организации работы,
- сколько сеансов пользователей возможно использовать одновременно,
- сколько файлов можно загружать с сервера одновременно,
- лучшее время для организации загрузки (если есть).
От этих вводных данных, а также от согласованной загрузки интернет-канала в вашем офисе будет сильно зависеть длительность процесса парсинга веб-приложения.
Если точных данных о максимально допустимой нагрузки нет, то можно имитировать обычную нагрузку на сервер веб-приложения, например, 4-5 пользователей могут работать одновременно, каждый из которых будет открывать по 8 страниц и ставить на скачивание по 16 файлов одновременно.
Подготовьте инфраструктуру для работы
Необходимо оценить примерный объем скачиваемой информации и подготовить жесткий диск или место на внутреннем сервере компании. Под проект можно временно арендовать облачное хранилище данных.
Необходимо согласовать использование трафика со своим IT-отделом, и выбрать время когда скачивать информацию. Возможно, когда канал в интернет не большой, то скачивать информацию можно будет только в нерабочие часы.
В зависимости от условий доступа к веб-приложению может потребоваться отдельный компьютер, зарегистрированный во внутренней сети компании.
Проанализируйте, какие данные вам нужны на самом деле
Необходимо определить какая именно информация будет скачиваться, какая информация нужна на самом деле для дальнейшей работы. Хорошей практикой будет предварительное получение какого-либо списка с искомой информацией, по которому можно будет организовать поиск нужных страниц в веб-приложении. Другой вариант: воспользоваться поиском и в автоматическом режиме получить ссылки на требуемые станицы из поисковой выдачи веб-приложения. Например, в поиске указать регион: Россия и проанализировать все страницы из результатов поиска.
Как правило, корпоративные системы сильно перегружены информацией на все случаи жизни. Конечно можно копировать все, но это будет дорого и долго. Лучшим вариантом будет определение требуемой структуры результирующих данных. Обычно веб-приложения представляют собой веб-интерфейс для работы с реляционной базой данных. Это значит, что информация может храниться в различных таблицах. Копируемые данные также могут сохраняться в различных таблицах, как это предполагается в исходной базе данных, или же каким-то другим требуемым образом.
Определите правила проверки копируемых данных. Иногда существующие данные могут содержать ошибки и не точности, которые можно и нужно исправить при организации копирования данных. Например: изменить формат дат и чисел, исправить опечатки, провести транслитерацию текста и так далее.
Перед началом разработки непосредственно программы-парсера важно определиться, как вы планируете использовать копируемую информацию в дальнейшем? Будет ли на основе полученных данных разрабатываться новое веб-приложение или данные будут импортироваться в уже существующее приложение? Какой у него будет функционал. Ответы на эти вопросы позволит настроить формат выходных данных оптимальным для дальнейшей работы образом.
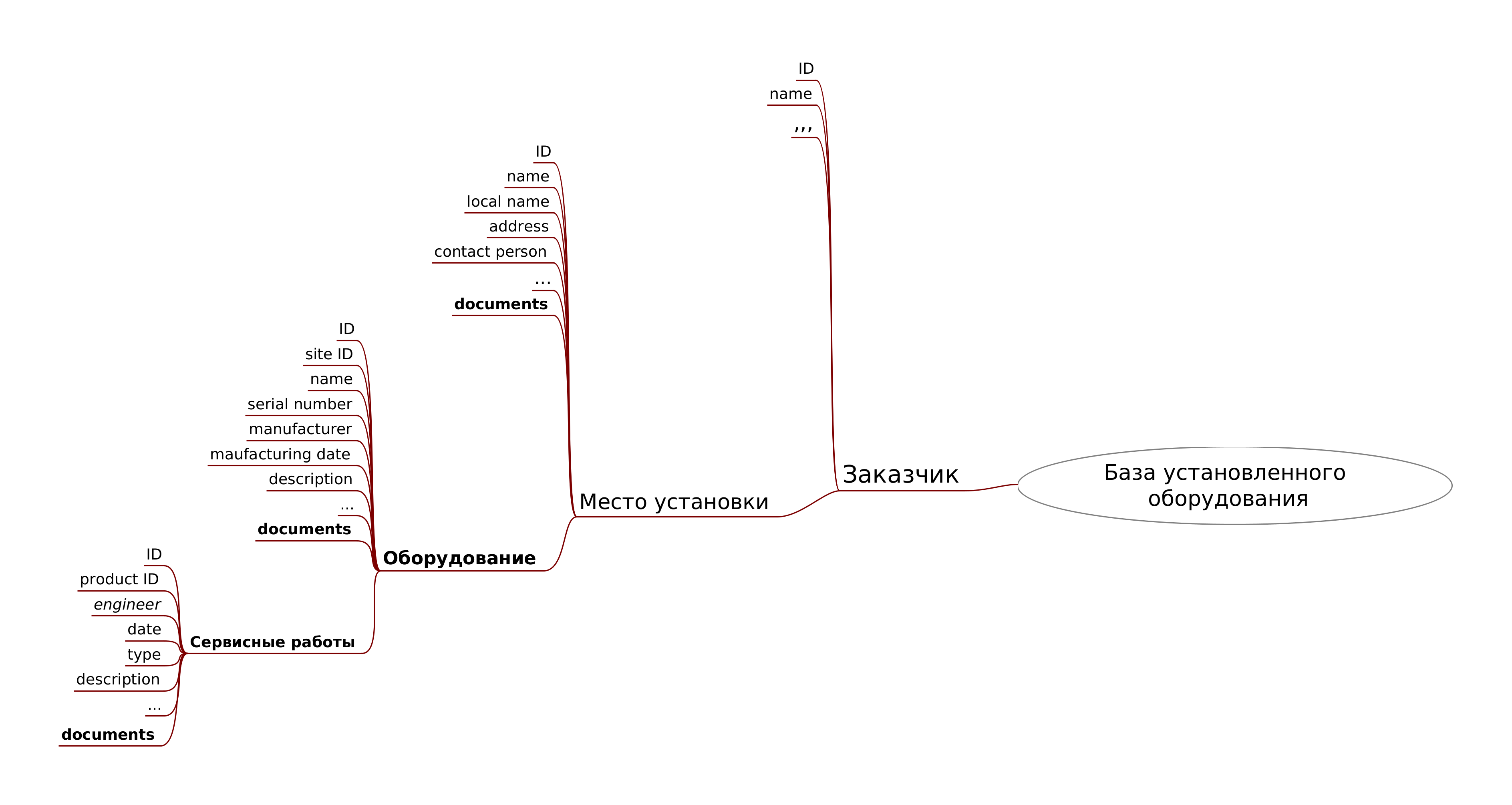
Схема данных для парсинга веб-сервиса установленного оборудования может выглядеть следующим образом:
У компании есть несколько заказчиков (customers), у каждого их которых есть несколько объектов (sites), где было установлено оборудование компании (installation).
На каждом объекте может быть установлено несколько различных типов оборудования компании.
Для каждого оборудования выполнялись сервисные работы (монтаж, инспекция, ремонт и т.д.), при этом оформлялось несколько соответствующих документов, копии которых сохранялись в базу данных.
Создание парсера
В целом создание парсера можно разделить на несколько этапов:
- Разработка и согласование технического задания.
- Анализ структуры данных на страницах веб-приложения.
- Разработка программы парсера.
- Тестирование программы парсера.
- Отладка парсера при работе непосредственно с веб-сервисом в локальной сети компании.
- Парсинг веб-сервиса. Мониторинг работы и аутентификации.
- Передача результатов работы.
На основе предварительного анализа задачи и изучения структуры данных целевого веб-сервиса создается специальная программа, которая позволит в автоматическом режиме скачать всю необходимую информацию локально на ваш диск или сетевой ресурс для дальнейшего использования.
В зависимости от структуры веб-страниц для сканирования и парсинга могут применяться различные фреймворки или библиотеки, например: Beautiful Soup, Selenium, Playwright, Scrapy и многие другие. Одни предназначены для парсинга простых веб-страниц, другие используют механизмы эмулирования действий пользователя в веб-браузере для получения требуемых данных от веб-приложения где на страницах контент формируется динамически.
Иногда для идентификации в веб-приложении может потребоваться двухфакторная аутентификация, например, ввод логина и пароля с последующим подтверждением, получаемым через телефон регистрируемого пользователя. В этих случаях для этого потребуется помощь оператора.
В зависимости от объема скачиваемой информации время работы парсера может достигать нескольких дней. График работы программы можно также настроить под требования и локальных системных администраторов, и администраторов веб-приложения (если есть).
Важно также определиться с максимально допустимыми лимитами для скачивания информации, чтобы не парализовать локальный канал в интернет или сервер веб-приложения. Если с локальным каналом определиться можно достаточно просто, то с максимально допустимой нагрузкой на сервер не всегда. Здесь также можно подойти гибко к вопросу: запланировать начало работы на одной скорости и постепенно её увеличить.
Парсер будет запоминать уже выполненную работу и в случае прерывания его в работе по каким-либо причинам сможет продолжить работу дальше.
Результаты работы
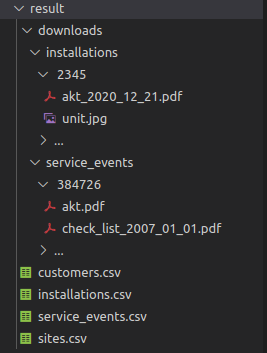
В результате работы парсера могут быть созданы таблицы в формате CSV или XLSX с данными из веб-сервиса. В таблицах в зависимости от требований в техническом задании будут также размещены ссылки на скопированные документы и ключи для связи с другими таблицами для возможности последующего импорта данных в какую-либо базу данных. Такой формат позволит также осуществлять поиск интересующей информации вручную.
Заключение
Информация - валюта XXI века. Она позволяет делать бизнес эффективнее и качественнее. Поэтому потерю информации нужно по возможности избегать. При возникновении такой ситуации с веб-сервисами уходящих из России компаний существуют решения по сохранению таких данных, даже если зарубежные компании не могут или не хотят вам помочь.
Одним из таких решений будет создание специальной программы - парсера, способной в автоматическом режиме просканировать нужный веб-сервис и сохранить для вас информацию со страниц веб-приложения, а также скачать все необходимые для дальнейшей работы файлы.
Такую программу можно гибко настроить, начиная со скорости загрузки информации с сервера и планирования графика работы, и заканчивая форматом сохраняемой информации.
Важно вовремя побеспокоиться об опасности потери важной информации и реализовать проект по копированию данных с веб-сервиса заранее.
Опубликовано: 19.02.2023